Instant OpenCV License Plate Recognition in iOS Apps with GPGPU

Founder & CEO at Azoft
Reading time:
Among other current optical character recognition (OCR) projects Azoft’s R&D team has been working on a new iOS app for reading Russian vehicle license plate numbers. Despite the immense popularity of the use of OCR technology by many mobile developers and researchers to accomplish this task, we still couldn’t find a real-time plate recognition solution for mobile platforms.
In our opining the key to real-time recognition lies in using GPU instead of relying on CPU. Recently, we have been working in this direction in several projects: Hydrodynamic Process Simulation, Barcode Scanner Mobile Application, Recognition of Credit Card Numbers, and Road Sign Recognition. Thus, we decided to take the challenge and write this app ourselves. Two major features that make Azoft’s solution unique are real-time processing of streaming video, and, as a result, instant number recognition — which became possible due to moving calculations to GPGPU. Today’s article includes a general algorithm that can easily be used in license plate recognition applications, along with all necessary snippets of shader code.
Practical usage
The development of a license plate recognition algorithm came as part of a larger project: an automobile “smart camera” app for cars that not only records what’s happening on the road ahead but notifies drivers about important roadway events such as the presence of construction warning signs, stationary objects in the road, etc. Another function of this ‘smart’ driving assistance technology is providing a “social networking platform” for auto enthusiasts — for which license number recognition was required. In our application, after the license plates of nearby vehicles have been read, a user can contribute to another user’s “karma ranking” — a user’s rank that reflects how much good he or she has done for the community — or send a private voice message. The app can also notify users if a driver with a low karma ranking is in the vicinity – provided the other driver has installed the app.
License plate recognition algorithm
A Russian number plate has the following layout: the number part at the left and a regional code at the right.

The typical stages in a plate recognition algorithm include:
- Localizing the plate in an image.
- Segmentation of plate characters.
- Character recognition.
Let’s look at these stages in more detail.
Plate localization
Our implementation of plate localization can be split to several key steps:
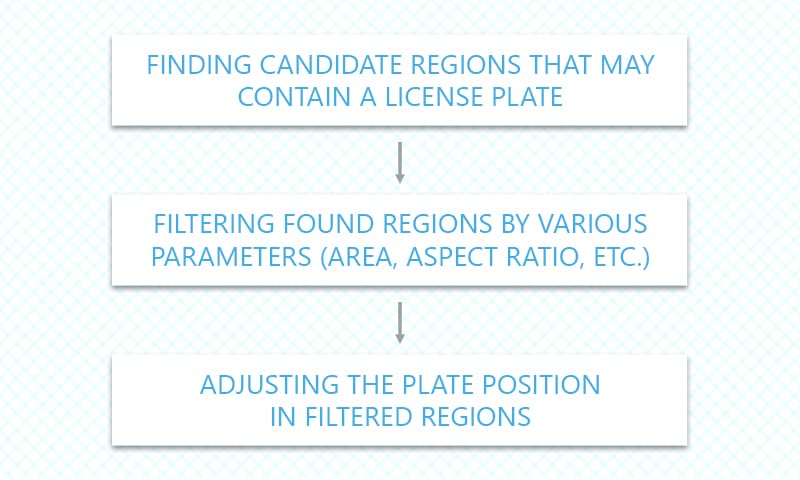
There’s an additional skew correction step that technically may be considered as part of the localization stage. The search for candidate regions is performed as a sequence of the following actions (all implemented using shaders in our project):
1. Converting camera image to grayscale

2. Applying the morphological operation Top Hat over the resulting image
A morphological operation called Top Hat is applied over the resulting image. It is a combination of dilation, erosion and subtraction of result from the previous grayscale image. Dilation and erosion use a structuring element defined by a 3×9 rectangle.
Dilation:

Erosion:

Subtraction:

3. Applying Sobel operator
Then we find the derivative of the resulting image using Sobel operator in horizontal direction.

4. Applying Gaussian blur
Next filter is Gaussian blur with 5×5 mask.

5. Closing
Closing (morphological) operation. It is a combination of dilation and erosion. Dilation and erosion use a structuring element defined by a 3×9 rectangle.


6. Otsu’s thresholding

To demonstrate the result, let’s see how processed image looks when combined with the over original grayscale image:

The proposed sequence of steps gives best results in our case, but it still can be changed, e.g. the closing operation and Otsu’s binarization can be swapped if required. To localize the plate in an image we used the following steps: Step 1. Find outlines in the binary image we got in the previous stage:
std::vector< std::vector > contours; cv::findContours(inputImg, contours, CV_RETR_EXTERNAL, CV_CHAIN_APPROX_NONE);
Step 2. Select outlines by ratio of outline area to athe area of bounding box (with a threshold of 0.45) and the actual area of bounding box:
std::vector rects;
std::vector<std::vector >::iterator itc = contours.begin();
while (itc != contours.end())
{
cv::RotatedRect mr = cv::minAreaRect(cv::Mat(*itc));
float area = fabs(cv::contourArea(*itc));
float bbArea=mr.size.width * mr.size.height;
float ratio = area/bbArea;
if( (ratio < 0.45) || (bbArea < 400) ){
itc= contours.erase(itc);
}else{
++itc;
rects.push_back(mr);
}
}
Step 3. All resulting rectangles (rects) are processed using steps 4-11. Step 4. The rectangle width and height is increased by dx and dy values, where dx and dy is chosen according to the bounding box dimensions (dx = 0.15126*width, dy = 0.625*height). This step is to make sure that the plate will be completely inside the rectangle for better results in further processing. Step 5. Extract part of the original grayscale image corresponding to the new rectangle. Step 6. Apply Otsu’s binarization using OpenCV with the following parameters:
cv::threshold(img, img_bin, 0, 255, CV_THRESH_OTSU+CV_THRESH_BINARY);
Step 7. Find outlines in the new binary image:
std::vector< std::vector > contours; cv::findContours(img_bin, contours, CV_RETR_EXTERNAL, CV_CHAIN_APPROX_NONE);
Step 8. Find the outline with the largest area. Step 9. Get the bounding box for this outline:
cv::RotatedRect mr = cv::minAreaRect(cv::Mat(*maxAreaContour));
Step 10. Check that the area, aspect ratio and skew for this bounding box are within tolerable limits.. Step 11. If the above condition is true, get the relevant part of grayscale image and apply skew correction. The result is scaled to a fixed size. The following image is passed to the segmentation stage:

Character segmentation
Character segmentation is performed using horizontal projection method. The regional code and the number part are segmented separately. First, we apply an adaptive filter of the grayscale image. It gives the least amount of noise compared to Otsu’s binarization or simple binarization (noise can appear if the plate is dirty or lit unevenly). The filter can be implemented using OpenCV with the following parameters:
cv::adaptiveThreshold(plate, plate, 255, cv::ADAPTIVE_THRESH_MEAN_C, cv::THRESH_BINARY, 13, 5);
The resulting binary image is projected onto a horizontal axis (called ProjX below):

The regional code is separated from the number with a solid line, thus ProjX will be minimal in the corresponding histogram region. If a plate has been localized with sufficient precision we can narrow down the boundaries for searching the minimal value. This is done to avoid false matches which can appear if other vertical lines are present in the image (e.g. plate outline). The range we suggest for looking for looking for regional code separator is [0.5*l ; 0.8*l], where l is the image width.
Character segmentation in the number area
To locate the digits in the number area, we’ll use first 10 highest values in ProjX. They will correspond to spacings between the digits. Actually there are 7 spaces, but certain letters may have worn out paint or the spacings may be darkened by dirt or shadows. To increase the probability of locating the spacings we use the value of 10. The lookup loop will also break if the current value if less than the first discovered value by a certain factor. The factor value was experimentally chosen to be 0.86 in our case. Some of the discovered positions can match a single spacing in the number or hit the digits, so the next step is to choose the 7 positions which have the highest probability of matching the actual spacings. To do that, of all the positions we choose 7 which have the lowest variance of distance between them. As the distance between 2 positions in a way matches the character width and all characters have the same width, the probability of filtering out redundant positions increases. The following illustration shows all discovered positions in colored lines. Green lines show those which have the lowest variance of distance between them.

To complete segmentation we have to find the coordinates of spaces which have a certain length, so each spacing is characterized by 2 coordinates: beginning and ending. Then we have to find vertical position of characters. This is done by cutting out the regions with characters from binary image and detecting edges inside them. Edge detection is also performed with OpenCV, but against the inverted images, i.e. we’ll be looking for white objects on a black background.
croppedImage = cv::Mat::ones(croppedImage.size(), croppedImage.type()) - croppedImage; std::vector<std::vector > v; findContours(croppedImage,v,CV_RETR_EXTERNAL,CV_CHAIN_APPROX_NONE);
For every outline we’ll have to get a bounding box using OpenCV function boundingRect(v[i]) and filter them by area and aspect ratio. The area of bounding box must fall into a range between 120 and 1000 and the aspect ratio should fall somewhere between 0.6 and 2.4. The horizontal boundaries of the digits thus will correspond to the coordinates of spaces and vertical boundaries will correspond to vertical boundaries of bounding boxes from the last step. We’re also looking into a possibility of vertical positioning of the characters using projection method like we do it for horizontal positioning.
Segmentation of characters in the regional code area
For horizontal positioning of characters we’ll use the projection method again. However, regional code area in Russia always contains letters “RUS” and Russian flag in the bottom part, so we can’t use the method immediately. These elements will affect horizontal projection and we won’t be able to detect spaces properly. The letters and the flag are always located in nearly the same place on number plates, so we can remove them from the projection data. To remove them, we simply exclude image data below the space between region code and the interfering letters and the flag. In the illustration below the space is green and the excluded data is red:

We still need to find the location of that space. We can do this by building a vertical projection of the regional code area and look for highest value. The search is again limited to some part of the image which the space might fall into. The limit also helps to exclude any extra spaces which may appear e.g. between the digits and the top outline. The vertical range for locating the space is something we need to find out now. It has to be chosen according to the lowest and highest possible region code position. In our example, vertical projection for the regional code will look like this:

Now we can go on with horizontal projection for the regional code area without worrying about anything below the digits. Maximum number of highest values will now be 5. Loop will also break if a highest value is less than first discovered maximum by a certain factor (we chose 0.825 after some experiments). Another problem is that the regional code may consist of 2 or 3 digits. The number of digits depends on the number of discovered spacings: if there are more than 3, then there are going to be 3 digits; if equal to 3, there are 2 digits. The rest of algorithm basically repeats the steps for the main part. The result of segmentation now looks like the following figure:

Gray rectangles indicate the characters to be recognized.
Character recognition
The recognition is implemented using convolutional neural network. There are 2 networks for recognition of letters and digits. The difference between them is the training data set and number of neurons in the last layer: 10 neurons for digits and 12 for letters (only 12 letters are used in Russian license plates).
Conclusion
The resulting application works in real time with a frame rate of 6-10 fps, when a plate is discovered and the number is recognized and 30-40 fps otherwise. The measurement results have been obtained on an iPad Air. Still, the prototype leaves much room for improvements, so we continue working on the project. Future improvements are planned to the localization and segmentation stages for higher success rate of plate number recognition and better performance. If you have worked on similar tasks we will appreciate if you could share your approaches and the results you received.


Comments